

2020. 12. 25. 17:09ㆍIT/PYTHON
리스트와 문자열은 굉장히 비슷합니다. 리스트가 어떤 자료형들의 나열이라면, 문자열은 문자들의 나열이라고 할 수 있겠죠. 지금부터 파이썬에서 리스트와 문자열이 어떻게 같고 어떻게 다른지 알아봅시다.
인덱싱 (Indexing)
두 자료형은 공통적으로 인덱싱이 가능합니다.
# 알파벳 리스트의 인덱싱
alphabets_list = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J']
print(alphabets_list[0])
print(alphabets_list[1])
print(alphabets_list[4])
print(alphabets_list[-1])
# 알파벳 문자열의 인덱싱
alphabets_string = 'ABCDEFGHIJ'
print(alphabets_string[0])
print(alphabets_string[1])
print(alphabets_string[4])
print(alphabets_string[-1])
for 반복문
두 자료형은 공통적으로 인덱싱이 가능합니다. 따라서 for 반복문에도 활용할 수 있습니다.
# 알파벳 리스트의 반복문
alphabets_list = ['C', 'O', 'D', 'E', 'I', 'T']
for alphabet in alphabets_list:
print(alphabet)
# 알파벳 문자열의 반복문
alphabets_string = 'CODEIT'
for alphabet in alphabets_string:
print(alphabet)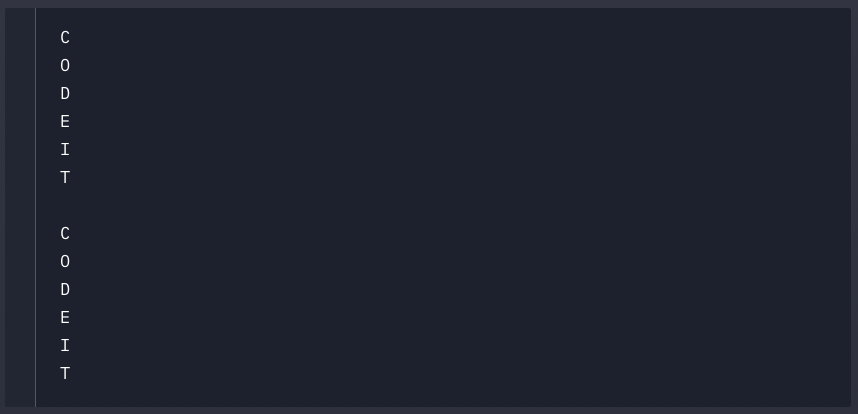
슬라이싱 (Slicing)
두 자료형은 공통적으로 슬라이싱이 가능합니다.
# 알파벳 리스트의 슬라이싱
alphabets_list = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J']
print(alphabets_list[0:5])
print(alphabets_list[4:])
print(alphabets_list[:4])
# 알파벳 문자열의 슬라이싱
alphabets_string = 'ABCDEFGHIJ'
print(alphabets_string[0:5])
print(alphabets_string[4:])
print(alphabets_string[:4])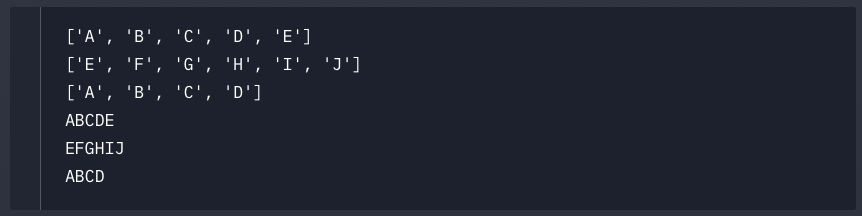
len 함수
두 자료형은 모두 길이를 재는 len 함수를 쓸 수 있습니다.
# 리스트의 길이 재기
print(len(['H', 'E', 'L', 'L', 'O']))
# 문자열의 길이 재기
print(len("Hello, world!"))
Mutable (수정 가능) vs. Immutable (수정 불가능)
하지만 차이점이 있습니다. 리스트는 데이터를 바꿀 수 있지만, 문자열은 데이터를 바꿀 수 없다는 것입니다. 리스트와 같이 수정 가능한 자료형을 'mutable'한 자료형이라고 부르고, 문자열과 같이 수정 불가능한 자료형을 'immutable'한 자료형이라고 부릅니다. 숫자, 불린, 문자열은 모두 immutable한 자료형입니다.
# 리스트 데이터 바꾸기
numbers = [1, 2, 3, 4]
numbers[0] = 5
print(numbers)
리스트 numbers의 인덱스 0에 5를 새롭게 지정해주었습니다. [5, 2, 3, 4]가 출력되었습니다. 이처럼 리스트는 데이터의 생성, 삭제, 수정이 가능합니다.
# 문자열 데이터 바꾸기
name = "codeit"
name[0] = "C"
print(name)
문자열 name의 인덱스 0 에 "C"를 새롭게 지정해주었더니 오류가 나왔습니다. TypeError: 'str' object does not support item assignment는 문자열은 변형이 불가능하다는 메시지입니다. 이처럼 문자열은 리스트와 달리 데이터의 생성, 삭제, 수정이 불가능합니다.
Q1. 함수 sum_digit은 파라미터로 정수형 num을 받고, num의 각 자릿수를 더한 값을 리턴합니다. 예를 들어서 12의 각 자릿수는 1, 2이니까 sum_digit(12)는 3(1 + 2)을 리턴합니다. 마찬가지로 486의 각 자릿수는 4, 8, 6이니까 sum_digit(486)은 18(4 + 8 + 6)을 리턴하는 거죠. 여러분이 해야 할 일은 두 가지입니다. sum_digit 함수를 작성한다. sum_digit(1)부터 sum_digit(1000)까지의 합을 구해서 출력한다.

#내 답안
# 자리수 합 리턴
def sum_digit(num_string):
# 코드를 입력하세요.
sum = 0
for num in num_string:
sum = sum + int(num)
return sum
# sum_digit(1)부터 sum_digit(1000)까지의 합 구하기
# 코드를 입력하세요.
sum = 0
for i in range(1,1001,1):
sum = sum + sum_digit(str(i))
print(sum)
#모범 답안
# 자리수 합 리턴
def sum_digit(num):
total = 0
str_num = str(num)
for digit in str_num:
total += int(digit)
return total
# sum_digit(1)부터 sum_digit(1000)까지의 합 구하기
digit_total = 0
for i in range(1, 1001):
digit_total += sum_digit(i)
print(digit_total)
Q2. 주민등록번호 YYMMDD-abcdefg는 총 열세 자리인데요. 앞의 여섯 자리 YYMMDD는 생년월일을 의미합니다.
YY → 연 MM → 월 DD → 일
뒤의 일곱 자리 abcdefg는 살짝 복잡합니다.
a → 성별
bc → 출생등록지에 해당하는 지방자치단체의 고유번호
defg → 임의의 번호
보시다시피 많은 부분은 특정 규칙대로 정해져 있는데요. 여러분에 대한 몇 가지 정보만 알면, 마지막 네 개 숫자 defg를 제외한 앞의 아홉 자리는 쉽게 알 수 있다는 거죠. 그래서 저희는 주민등록번호의 마지막 네 자리 defg만 가려 주는 보안 프로그램을 만들려고 합니다. mask_security_number라는 함수를 정의하려고 하는데요. 이 함수는 파라미터로 문자열 security_number를 받고, security_number의 마지막 네 글자를 '*'로 대체한 새 문자열을 리턴합니다. 참고로 파라미터 security_number에는 작대기 기호(-)가 포함될 수도 있고, 포함되지 않을 수도 있는데요. 작대기 포함 여부와 상관 없이, 마지막 네 글자가 '*'로 대체되어야 합니다!
# 내답안
def mask_security_number(security_number):
# 코드를 입력하세요.
sum = ""
if 14 == len(security_number):
i = 1
for num in security_number:
if i <= 10:
#print(num, end='')
sum += num
else:
#print("*", end='')
sum += "*"
i += 1
else:
i = 1
for num in security_number:
if i <= 9:
#print(num, end='')
sum += num
else:
#print("*", end='')
sum += "*"
i += 1
return sum
# 테스트
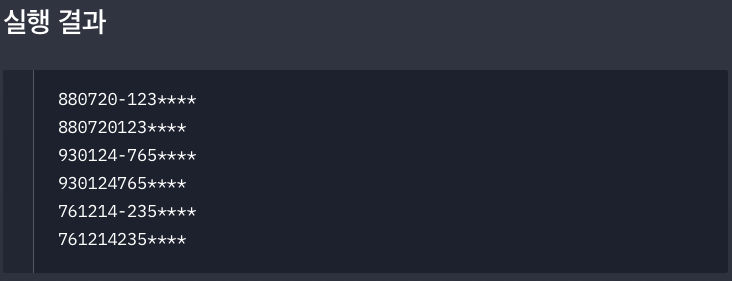
print(mask_security_number("880720-1234567"))
print(mask_security_number("8807201234567"))
print(mask_security_number("930124-7654321"))
print(mask_security_number("9301247654321"))
print(mask_security_number("761214-2357111"))
print(mask_security_number("7612142357111"))
#모범답안
def mask_security_number(security_number):
return security_number[:-4] + '****'
# 테스트
print(mask_security_number("880720-1234567"))
print(mask_security_number("8807201234567"))
print(mask_security_number("930124-7654321"))
print(mask_security_number("9301247654321"))
print(mask_security_number("761214-2357111"))
print(mask_security_number("7612142357111"))
Q3. "토마토"나 "기러기"처럼 거꾸로 읽어도 똑같은 단어를 '팰린드롬(palindrome)'이라고 부릅니다.
팰린드롬 여부를 확인하는 함수 is_palindrome을 작성하려고 하는데요. is_palindrome은 파라미터 word가 팰린드롬이면 True를 리턴하고 팰린드롬이 아니면 False를 리턴합니다.
예를 들어서 "racecar"과 "토마토"는 거꾸로 읽어도 똑같기 때문에 True가 출력되어야 합니다. 그리고 "hello"는 거꾸로 읽으면 "olleh"가 되기 때문에 False가 나와야 하는 거죠.

# 내 답안
def is_palindrome(word):
# 코드를 입력하세요.
# 정방향 출력
i = 0
while i < len(word):
#print(word[i], end='')
i = i + 1
j = len(word) -1
string_sum = ""
# 역방향 출력
while j >= 0:
string_sum += word[j]
#print(word[j], end='')
j = j - 1
if word == string_sum:
return True
else:
return False
# 테스트
print(is_palindrome("racecar"))
print(is_palindrome("stars"))
print(is_palindrome("토마토"))
print(is_palindrome("kayak"))
print(is_palindrome("hello"))
# 모범답안
def is_palindrome(word):
for left in range(len(word) // 2):
# 한 쌍이라도 일치하지 않으면 바로 False를 리턴하고 함수를 끝냄
right = len(word) - left - 1
if word[left] != word[right]:
return False
# for문에서 나왔다면 모든 쌍이 일치
return True
# 테스트
print(is_palindrome("racecar"))
print(is_palindrome("stars"))
print(is_palindrome("토마토"))
print(is_palindrome("kayak"))
print(is_palindrome("hello"))'IT > PYTHON' 카테고리의 다른 글
| [PYTHON] 숫자 야구: 프로젝트 (0) | 2020.12.27 |
|---|---|
| [PYTHON] 로또시뮬레이션 (0) | 2020.12.27 |
| [PYTHON] 파일 읽고 쓰기(과제 : 코딩에 빠진 닭, 단어장만들기, 단어퀴즈, 고급단어장) (0) | 2020.12.26 |
| [PYTHON] RANDOM 모듈, DATETIME 모듈, INPUT함수(과제 : 숫자맞추기 게임) (0) | 2020.12.26 |
| [파이썬] 사전(Dictionary) 문제 / 정답 (0) | 2020.12.19 |
| [파이썬] for와 range 과제 (0) | 2020.12.18 |
| [파이썬] 리스트와 인덱싱 연습문제 (0) | 2020.12.17 |
| [파이썬] while, if 문제 (0) | 2020.12.16 |