

2023. 8. 27. 18:38ㆍ인공지능
WSL 설치하기
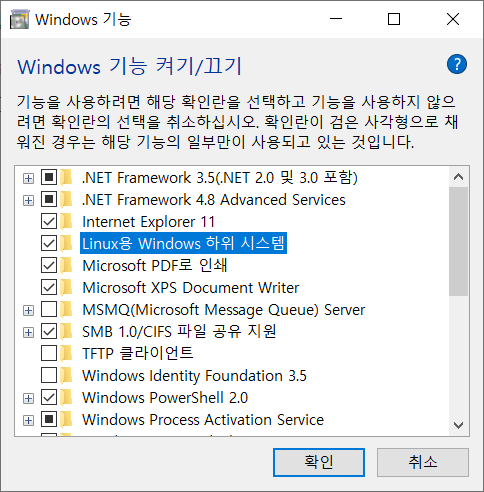
시작 → 실행 → 제어판(config 입력) → 프로그램 → Windows 기능 켜기/끄기 → Linux용 Windows 하위 시스템 체크 → 확인


Ubuntu 다운로드
도스프롬프트에서 wsl 라고 입력하면, 배포판이 설치되어 있지 않다고 메시지가 나옵니다.
| Microsoft Windows [Version 10.0.19044.2006] (c) Microsoft Corporation. All rights reserved. C:\Users\Hyungwon>wsl Linux용 Windows 하위 시스템에 배포가 설치되어 있지 않습니다. 아래의 Microsoft Store에서 배포를 설치할 수 있습니다. https://aka.ms/wslstore |
윈도우 스토어에 들어가서 ubuntu 라고 검색하고 제일 최신 버전을 설치합니다.
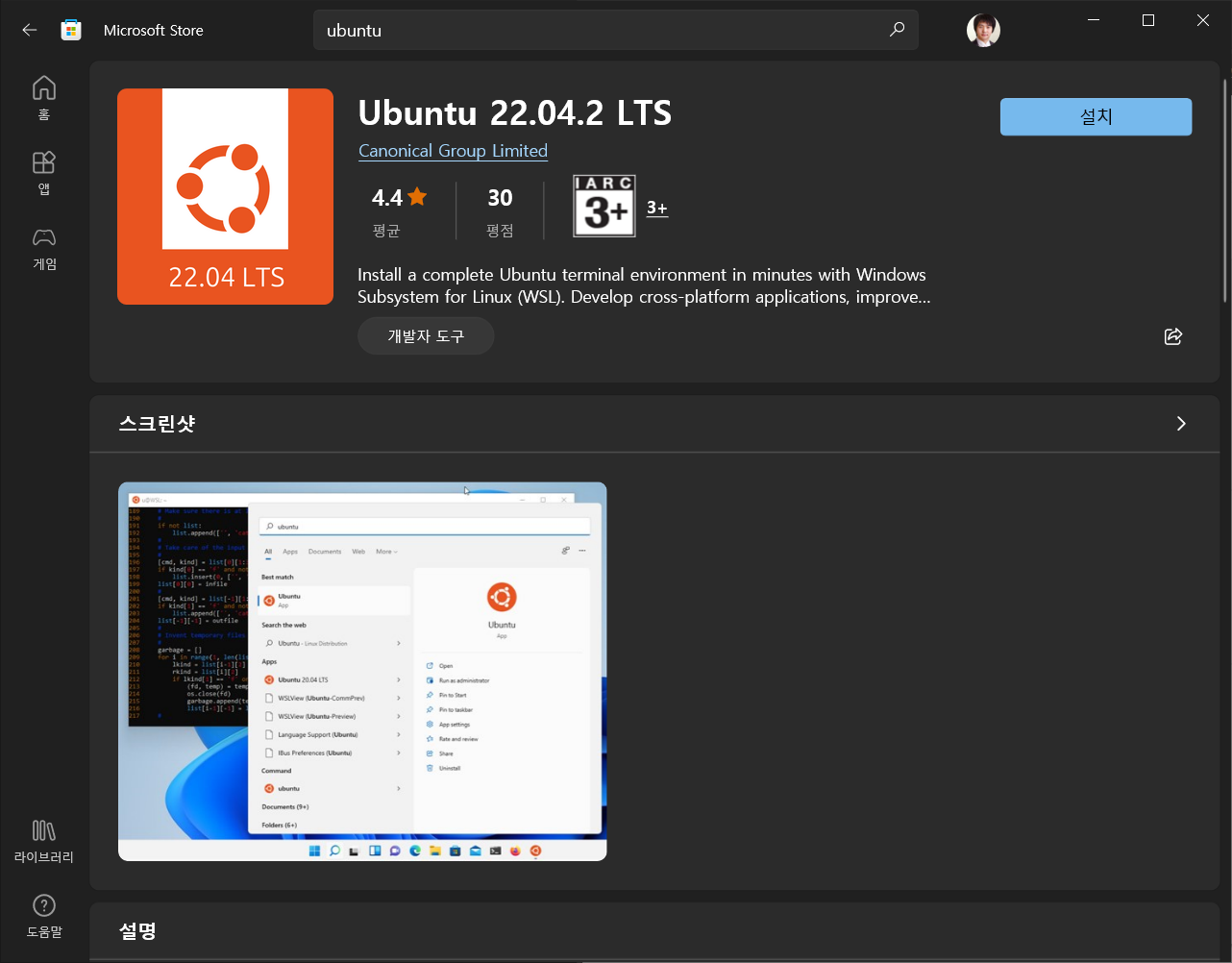
다운로드 및 설치가 완료 되면 [열기] 버튼이 활성화되는데 그것을 클릭합니다.

username과 password를 입력합니다.

우바부가 설치
아래 사이트를 방문해서 합니다.
GitHub - oobabooga/text-generation-webui: A Gradio web UI for Large Language Models. Supports transformers, GPTQ, llama.cpp (ggml/gguf), Llama models.
GitHub - oobabooga/text-generation-webui: A Gradio web UI for Large Language Models. Supports transformers, GPTQ, llama.cpp (ggm
A Gradio web UI for Large Language Models. Supports transformers, GPTQ, llama.cpp (ggml/gguf), Llama models. - GitHub - oobabooga/text-generation-webui: A Gradio web UI for Large Language Models. S...
github.com
먼저 미니콘다를 설치합니다.
미니 화면에서 안내하는대로 라이선스 동의 등의 키값을 입력합니다.
| curl -sL "https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh" > "Miniconda3.sh" bash Miniconda3.sh |
그럼 미니콘다가 자동으로 설치가 됩니다.

우바부가 환경 생성하기
WSL를 닫았다가 다시 도스프롬프트에서 wsl를 입력합니다. 그리고 아래의 명령어를 순서대로 입력해주세요. 필요한 패키지들이 자동으로 설치가 됩니다.
| conda create -n textgen python=3.10.9 conda activate textgen |

파이토치 설치하기
최신 버전으로 일단 업데이트를 해줍니다.
| sudo apt-get update sudo apt-get upgrade |
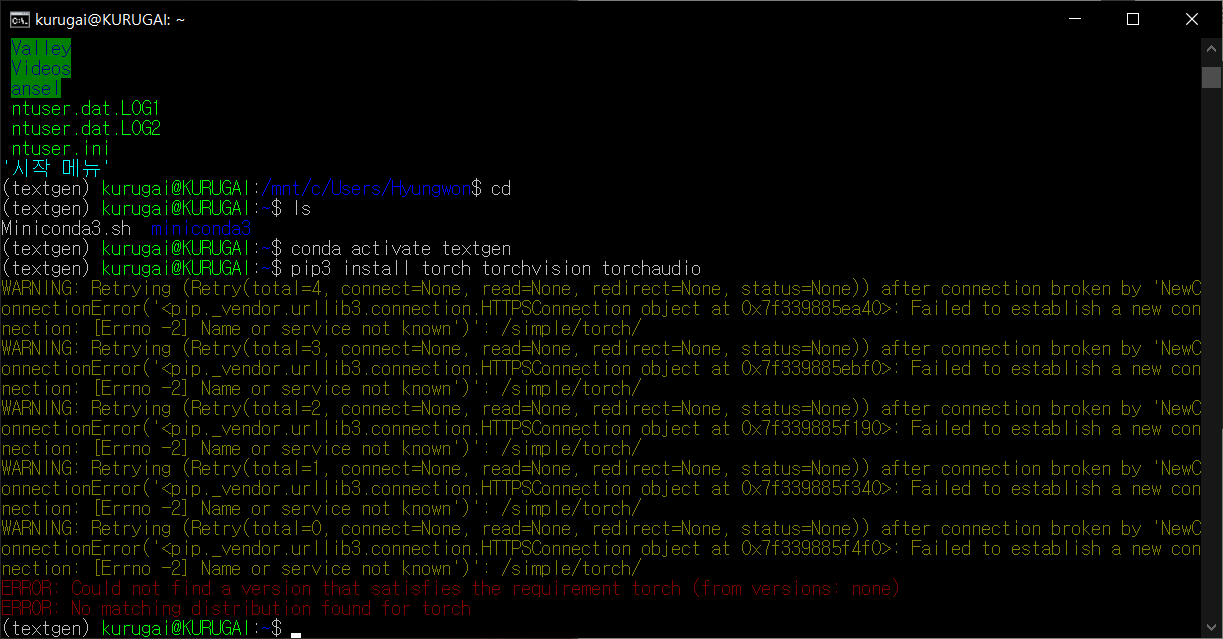
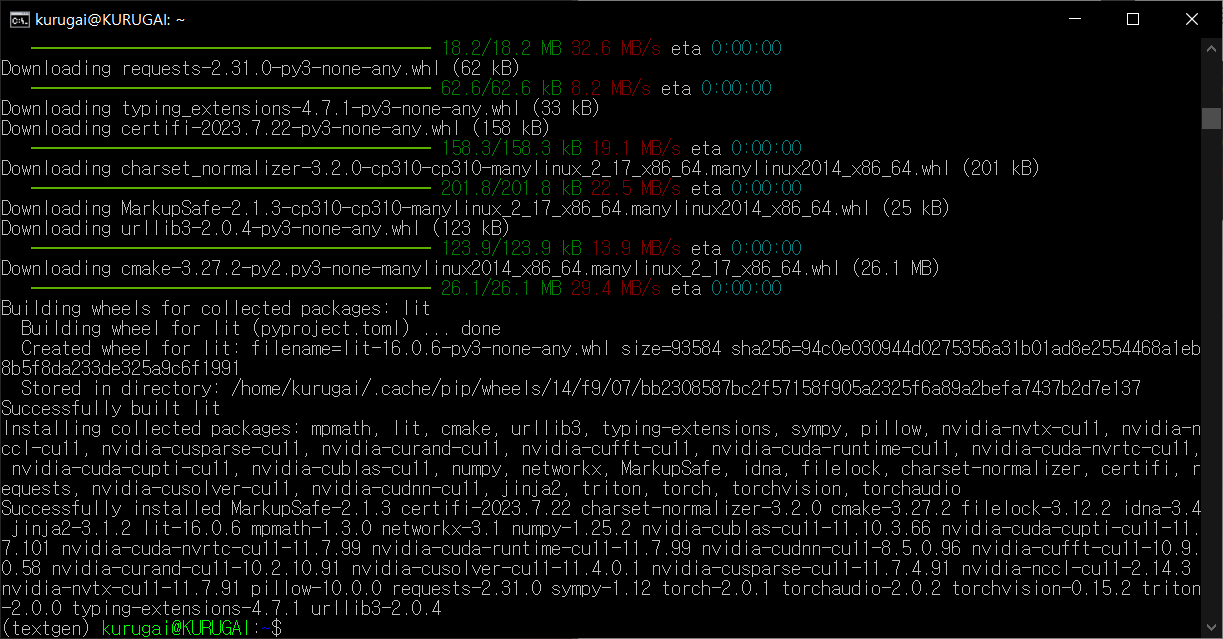
파이토치를 pip로 설치합니다.
| pip install torch torchvision torchaudio |
우바부가 설치하기
git 명령어로 우바부가를 다운로드 받고, 필요한 패키지들을 설치합니다. 중간에 빠진 모듈도 설치해줍니다.
| git clone https://github.com/oobabooga/text-generation-webui cd text-generation-webui sudo apt-get install gcc pip install -r requirements.txt pip install gradio pip install markdown pip install transformers pip install accelerate pip install datasets pip install peft sudo apt install g++ gdb make ninja-build rsync zip pip install llama-cpp-python |
아래의 명령어로 우바부가를 실행합니다.
| python server.py --auto-launch --api --n_ctx 2048 --auto-devices --load-in-4bit |
아래와 같이 `http://127.0.0.1:7860`가 표시되고 웹브라우저에서 주소를 입력하면 성공입니다.


우바부가 MODEL 다운로드 및 로드
저는 GPU가 좋지 못해서 GGML 모델로 다운로드 했습니다. GGML 모델은 CPU로만 작동해서 GPU가 없어도 LLM을 구동할 수 있습니다.

2023--8-27 현재 GGML 포맷은 폐기(?)되었고 GGUF라는 새로운 포맷만이 로드할 수 있습니다. 변환하는 방법은 나중에 기입하겠습니다. 당분간 못쓰겠네요 -_-
GGML에서 GGUF로 변환하기
| pip install gguf |
(textgen) kurugai@KURUGAI:~/llama-cpp$ python convert-llama-ggmlv3-to-gguf.py --input models/Llama-2-ko-7B-chat-ggml-q4_
1.bin --output q4.bin
* Using config: Namespace(input=PosixPath('models/Llama-2-ko-7B-chat-ggml-q4_1.bin'), output=PosixPath('q4.bin'), name=None, desc=None, gqa=1, eps='5.0e-06', context_length=2048, model_metadata_dir=None, vocab_dir=None, vocabtype='spm')
=== WARNING === Be aware that this conversion script is best-effort. Use a native GGUF model if possible. === WARNING ===
* Scanning GGML input file
* GGML model hyperparameters: <Hyperparameters: n_vocab=46336, n_embd=4096, n_mult=5504, n_head=32, n_layer=32, n_rot=128, n_ff=11008, ftype=3>
=== WARNING === Special tokens may not be converted correctly. Use --model-metadata-dir if possible === WARNING ===
* Preparing to save GGUF file
* Adding model parameters and KV items
* Adding 46336 vocab item(s)
* Adding 291 tensor(s)
gguf: write header
gguf: write metadata
gguf: write tensors
* Successful completion. Output saved to: q4.bin'인공지능' 카테고리의 다른 글
| RTX 8000를 사용해 LLM을 찍먹해보았습니다. (2) | 2024.01.27 |
|---|---|
| F1 Score 측정하는 프로그램 (0) | 2023.10.30 |
| Deepl API를 이용하여 영어를 한국어로 변환하기 (1) | 2023.09.20 |
| github의 llama_cpp.server에 lora 기능을 추가해달라고 요청했다! (0) | 2023.09.19 |
| 딥러닝 기초 용어 정리( Epoch, Loss, Accuracy) (0) | 2023.08.26 |
| [LLM] 인공지능 챗으로 동맥경화에 대해서 상담을 받아보았습니다. (0) | 2023.08.21 |
| [LLM] 우바부가 API로 gradio 연동하기 (0) | 2023.08.17 |
| 임베딩 개념 이해 (0) | 2023.08.02 |