

2023. 8. 17. 08:01ㆍ인공지능

안녕하세요. 쿠루가이입니다.
오늘은 text-generation-webui(이하 우바부가)에서 외부로 통신하는 방법에 대해서 알아보겠습니다.
컴퓨터 사양
저는 2021년 2월에 컴퓨터를 새로 맞췄습니다. 사양은 아래와 같습니다.
|
그때 당시에는 LLM을 할거라는 생각을 전혀 하지 못했습니다. 그래서 QHD로 오버워치가 144Hz로 동작만 한다면 아무 문제 없다고 생각했었는데...지금 와서 보면 완전 멍청한 짓이였습니다.ㅠㅠ

LLM을 돌리기엔 VRAM 8GB는 정말 최소 사양이기때문입니다. 뭐 제가 LLM을 할지....몰랐기 때문에 이런 선택을 한것이지요^^;; 하지만 7b모델 / 양자화 4bit로 하면 어느정도 돌아가기 때문에 그래도 LLM에 비벼볼 만은 합니다.
우바부가 설치 환경
우바부가 설치는 우분투나 WSL 환경에서 설치를 권합니다. 윈도우에서 설치하면...'bitsandbytes' 모듈에서 자꾸 막혀서 설치하는데 시간을 많이 보내게 됩니다. 저는 하다가 잘 안되서 포기하고 WSL 환경으로 옮겼는데....한방에 설치되서...좀 짜증이 났었습니다^^;;
GitHub - oobabooga/text-generation-webui: A Gradio web UI for Large Language Models. Supports transformers, GPTQ, llama.cpp (ggml), Llama models.
GitHub - oobabooga/text-generation-webui: A Gradio web UI for Large Language Models. Supports transformers, GPTQ, llama.cpp (ggm
A Gradio web UI for Large Language Models. Supports transformers, GPTQ, llama.cpp (ggml), Llama models. - GitHub - oobabooga/text-generation-webui: A Gradio web UI for Large Language Models. Suppor...
github.com
우바부가 API 기동하기
우바부가가 설치된 폴더로 이동하여 아래와 같이 커맨드를 입력하면 API 를 사용할 수 있게 기동됩니다.
python server.py --auto-launch --api --n_ctx 2048 --auto-devices --gpu-memory 7 --load-in-4bit --model kfkas_Llama-2-ko-7b-Chat간단히 주요 옵션을 설명 드리자면....
- -- n_ctx 2048 : context 길이를 2k로 하겠다는 옵션입니다.
- --api : 외부와 우바부가간 통신하게 해주는 옵션입니다.
- --gpu-memory 7 : gpu메모리를 7GB로 제한하는 옵션입니다. 메모리 터지는걸 방지하려고 사용했습니다.
- --load-in-4bit : 4비트로 양자화하는 옵션입니다. 성능이 낮은 gpu를 가진 저에게는 정말 축복같은 옵션입니다.
- --model : 어떤 LLM을 사용할 것인가를 정해주는 옵션입니다. 저는 비교적 답변을 잘하는 'kfkas_Llama-2-ko-7b-Chat'을 사용했습니다. 이 모델이 답변을 잘하더라고요.
우바부가 API와 연동하고 gradio로 채팅하기
우바부가 API 샘플코드에 gradio 샘플코드를 붙여서 제작했습니다.(키메라?)
import requests
import gradio as gr
# For local streaming, the websockets are hosted without ssl - http://
HOST = 'localhost:5000'
URI = f'http://{HOST}/api/v1/generate'
# For reverse-proxied streaming, the remote will likely host with ssl - https://
# URI = 'https://your-uri-here.trycloudflare.com/api/v1/generate'
def run(prompt):
request = {
'prompt': prompt,
'max_new_tokens': 2048,
# Generation params. If 'preset' is set to different than 'None', the values
# in presets/preset-name.yaml are used instead of the individual numbers.
'preset': 'None',
'do_sample': True,
'temperature': 0.7,
'top_p': 0.1,
'typical_p': 1,
'epsilon_cutoff': 0, # In units of 1e-4
'eta_cutoff': 0, # In units of 1e-4
'tfs': 1,
'top_a': 0,
'repetition_penalty': 1.18,
'repetition_penalty_range': 0,
'top_k': 40,
'min_length': 0,
'no_repeat_ngram_size': 0,
'num_beams': 1,
'penalty_alpha': 0,
'length_penalty': 1,
'early_stopping': False,
'mirostat_mode': 0,
'mirostat_tau': 5,
'mirostat_eta': 0.1,
'seed': -1,
'add_bos_token': True,
'truncation_length': 2048,
'ban_eos_token': False,
'skip_special_tokens': True,
'stopping_strings': ["<|endoftext|>", "### ", "~~", "~", "H"]
}
response = requests.post(URI, json=request)
if response.status_code == 200:
result = response.json()['results'][0]['text']
return result
def respond(message, chat_history):
result = run("아래는 작업을 설명하는 명령어입니다. 요청에 적절히 완료하는 응답을 대화 형식으로 부드럽게 작성해주세요. 그리고 모른다는 답변은 하지 마세요. ### 명령어: " + message +"\n\n ### 응답:")
bot_message = f'{result}'
chat_history.append((message, bot_message))
return "", chat_history
with gr.Blocks(theme=gr.themes.Soft()) as demo:
gr.Markdown("# 안녕하세요. Llama-2-ko-7b-chat 모델과 대화해보세요.")
initial_greeting = "안녕하세요!\n저는 인공지능 Llama-2-ko-7b-chat입니다. 질문이 있으시면 편안하게 물어보세요!"
chatbot = gr.Chatbot(label="채팅창", value=[(None, initial_greeting)])
msg = gr.Textbox(label="입력")
clear = gr.Button("초기화")
msg.submit(respond, [msg, chatbot], [msg, chatbot])
clear.click(lambda: None, None, chatbot, queue=False)
if __name__ == '__main__':
demo.launch(debug=False)이 우바부가로 llama2 LLM을 돌리면 대략적으로 5GB VRAM을 먹습니다. 여기서 토큰을 생성하는 도중에 더 올라갈 수 도 있는데 램오버 난 적은 없었습니다. 우바부가가 저사양을 위한 옵션이 많아서 그런지 API로 하면 VRAM 오버 현상이 나지 않더라고요. 그냥 쌩으로 파이썬으로 돌리면 좀 어려운 문장? 이런거 말하면 바로 VRAM 오버 현상이 나왔거든요.ㅠㅠ
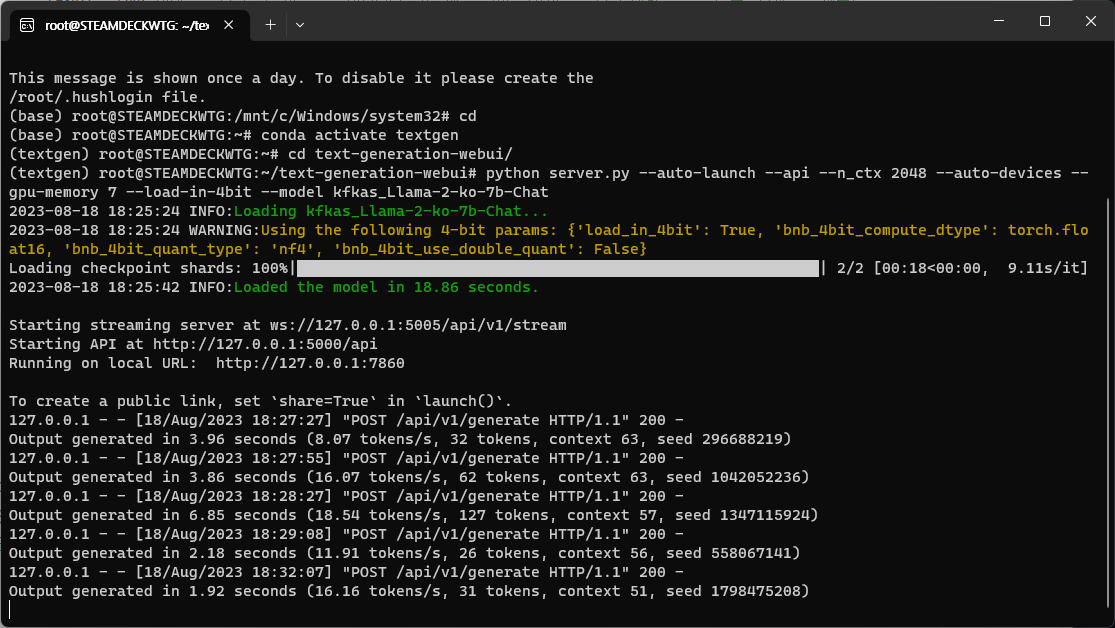
실제로 실행을 해보면 아래와 같이 답변을 하는것을 확인할 수 있습니다.

3070은 초당 생성 토큰이 8~16정도로 좀 느린데 기다릴만합니다.
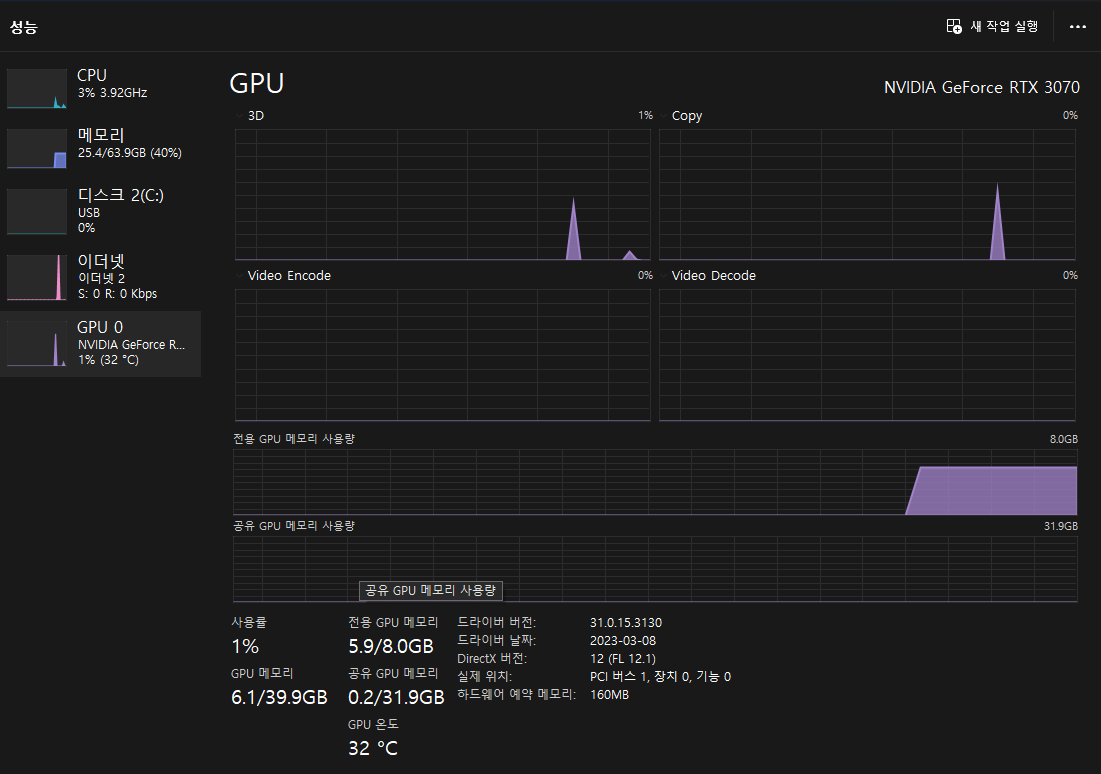
질답을 끝내고 얼마나 자원을 사용했는지 확인해보았는데, 아직...VRAM이 2GB 정도 여유 있는것을 확인할 수 있었습니다. 하지만 불안 불안 합니다.ㅠㅠ
반복적인 말이 나올 때 어떻게 하나?
LLM을 돌리다보면 반복적인 질문, 답변을 하는 경우가 많습니다. 그럴 경우, 소스의 run() 함수 부분에 stopping_string 이라는 속성이 있거든요. 이것의 의미는 여기에 등록된 string이 나오면 답변을 끊겠다는 의미입니다. llama2의 경우, </s>로 문장이 끝나는 경우가 많은데 어차피 </s>가 나왔다는것은 LLM이 문장을 다 완성했다는 의미이기때문에 굳이 등록할 필요는 없습니다. 다만 소스에서 프롬프트를 '### 명령어', '### 응답' 이런식으로 포맷이 맞춰져있기 때문에 '### '가 나오면 굳이 토큰을 생성할 필요가 없어지므로, '### '를 등록해놓았습니다. 의미없는 토큰 생성을 미연에 방지하려면 무조건 등록해놓는것이 좋습니다. 안 그럼 한없이 기다려야 합니다^^;;
Lora를 붙여서 쓰면....또 다른 유형의 반복적인 말들이 나오는데 이것도 하나하나 등록해놓으면 나름 쾌적해 집니다.
'인공지능' 카테고리의 다른 글
| F1 Score 측정하는 프로그램 (0) | 2023.10.30 |
|---|---|
| Deepl API를 이용하여 영어를 한국어로 변환하기 (1) | 2023.09.20 |
| github의 llama_cpp.server에 lora 기능을 추가해달라고 요청했다! (0) | 2023.09.19 |
| WSL에 우바부가 설치하기 (2) | 2023.08.27 |
| 딥러닝 기초 용어 정리( Epoch, Loss, Accuracy) (0) | 2023.08.26 |
| [LLM] 인공지능 챗으로 동맥경화에 대해서 상담을 받아보았습니다. (0) | 2023.08.21 |
| 임베딩 개념 이해 (0) | 2023.08.02 |
| 파인튜닝 시, step 수는 몇으로 해야하는지 알아보자. (0) | 2023.07.13 |